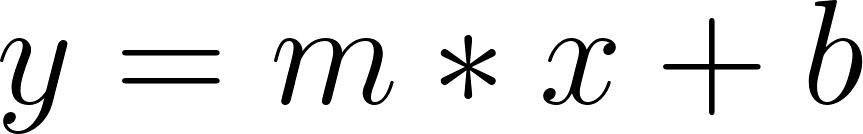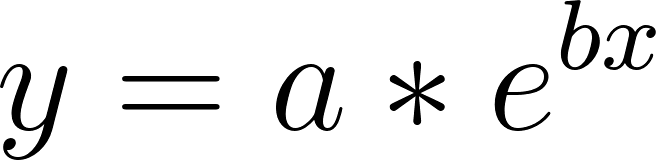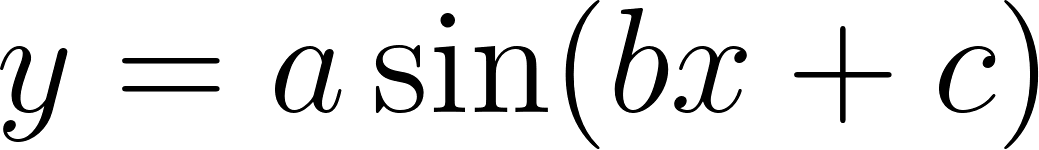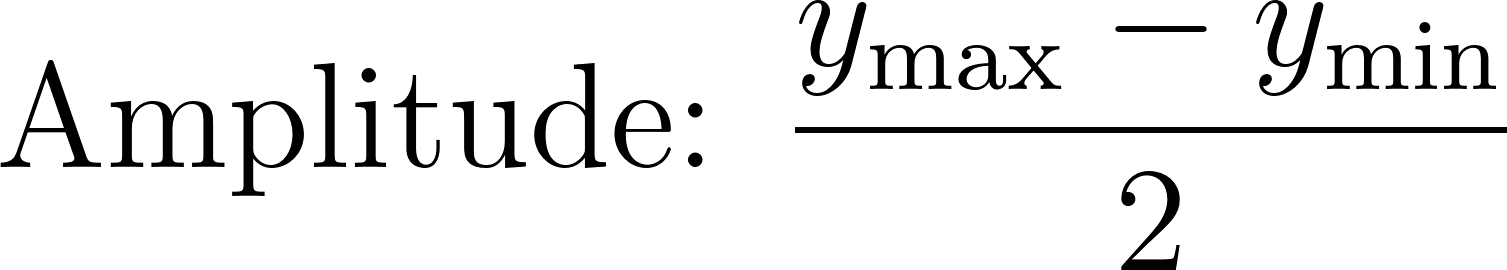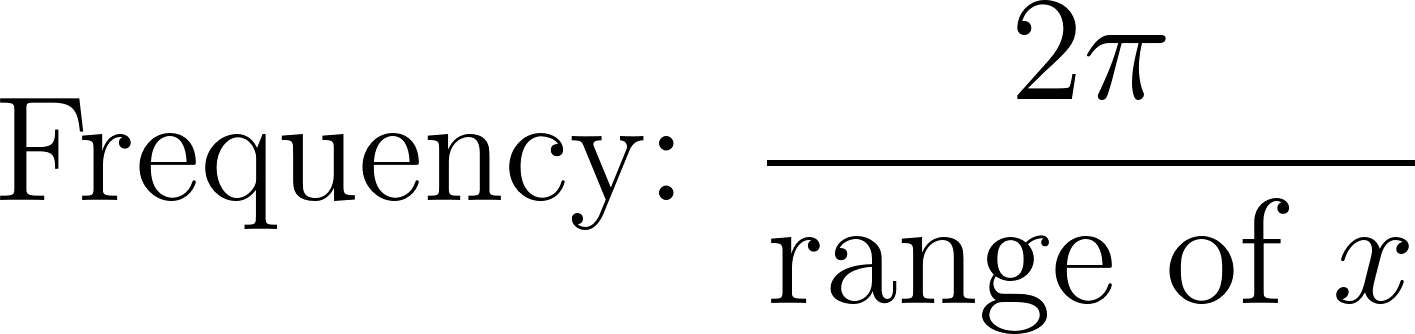This document contains a series of programming problems designed to help you practice plotting graphs with Python. Tasks 6 and 7 involve working with datapoints provided in some .csv files – They’re hyperlinked in the problem description, but they can also be found here: Problem Set Data
|
Function |
Purpose |
Example Syntax |
|
plt.plot(x, y) |
Plot a line connecting x and y values. |
plt.plot(years, population) |
|
plt.title() |
Add a title to the plot. |
plt.title("Population Over Years") |
|
plt.xlabel() |
Label the x-axis. |
plt.xlabel("Years") |
|
plt.ylabel() |
Label the y-axis. |
plt.ylabel("Population (Billions)") |
|
plt.grid() |
Add gridlines to the plot. |
plt.grid(True) |
|
plt.show() |
Display the plot. |
plt.show() |
|
sns.barplot() |
Create a bar graph |
sns.barplot(x=categories, y=values) |
|
sns.histplot() |
Plot a histogram. |
sns.histplot(data, bins=10, kde=True) |
|
sns.heatmap() |
Create a heatmap |
sns.heatmap(data, annot=True) |
|
np.random.randint() |
Generate random integers |
np.random.randint(18, 60, 100) |
|
np.random.rand() |
Generate random float values |
np.random.rand(6, 6) |
Objective
Visualize trends in a dataset using a line plot.
Instructions:
Hint: Use plt.plot() to draw the line and customize the style with arguments like color, linestyle, and marker.
Objective: Use a bar graph to compare data categories.
Instructions:
Hint: Use sns.barplot() for the bar graph and plt.text() to annotate the bars.
Objective: Visualize the distribution of a dataset using a histogram.
Instructions:
Hint: Use sns.histplot() for the histogram and enable the kde argument.
Objective: Visualize correlations between data points using a heatmap.
Instructions:
Hint: Use sns.heatmap() and enable the annot=True argument to show the values inside the cells.
Objective:
Visualize training and testing accuracies for different models using a grouped bar chart.
Instructions:
Example:
models = ["Model A", "Model B", "Model C", "Model D"] |
Example
# Pastel color palette of size 2 custom_palette = sns.color_palette("pastel", 2) |
Example
# Plot the bars |
Data Source: UN WPP (2024); HMD (2024); Zijdeman et al. (2015); Riley (2005)OurWorldinData.org/life-expectancy
Your task is to analyze life expectancy data from a CSV file, focusing on specific countries, and compare their trends over time.
Load the life expectancy dataset and make it easier to work with.
Instructions:
Hint: To rename columns, use the rename() method. To convert column names to lowercase, use .str.lower() on the column.
Example:
# Rename a column # Convert data in "country" and "code" columns to lowercase for easier matching df['country'] = df['country'].str.lower() df['code'] = df['code'].str.lower() |
Ask the user to select one or more countries (using their names or codes) for analysis.
Instructions:
Hint: Use pandas filtering to check if the input matches values in the "country" or "code" columns.
Example:
# Check if a value exists in a column |
Find the earliest year for which all the selected countries have data.
Instructions:
Hint: Use Python sets to find the common years, then the min() function to find the minimum year.
Example:
# Find the intersection of two sets |
Filter the DataFrame to only include rows from the minimum common year onward.
Instructions:
Hint: To filter data by a condition, use pandas slicing.
Example:
# Filter rows where column values are greater than or equal to a threshold |
Plot the life expectancy data for the selected countries, either alone or compared to the world average.
Instructions:
Hint: Use the plot() function from matplotlib to plot line graphs.
Example:
# Plot a line graph |
Experiment with customizing the plot by changing colors, adding gridlines, or modifying line styles.
Task:
Hint:
Example:
# Add gridlines and save the plot |
You are provided with three datasets (mystery1.csv, mystery2.csv, mystery3.csv) in the Drive folder. Each .csv contains 2 columns of x and y values. Your task is to:
Instructions:
amplitude_guess = (y.max() - y.min()) / 2 |
If you’re stuck:
#List to store our results for each curve fit attempt results = [] |
# Linear fit |
# Exponential fit |
# Sinusoidal fit (after estimating initial parameters) y_sinusoidal_fit = sinusoidal_func(x, *popt_sinusoidal) mse_sinusoidal = np.mean((y - y_sinusoidal_fit) ** 2) results.append(("Sinusoidal", y_sinusoidal_fit, mse_sinusoidal, "purple")) |
# Plot the original data and best-fit curves |